
















Haskellが難しい理由
- 他の言語ではstring型でやっていることをString, Text, ByteString, Lazy.Text, Lazy.ByteStringなど様々な型がある
- 初心者の目にはコードがパースできない
lift . void . forkIO . runResourceT $ sourceStdIn $$ textEventSource =$ sinkChan chan
それぐらいだと思う。
Haskellのコンパイル中に現れるSTGと, GDBで見るC-backendなC--
Haskellのプログラムの実行がGlasgow Haskell Compilerによるコンパイル後にどういう命令によって表現されているかに興味があったので調べてみました. 例えば関数がどのようにメモリ上に存在するかといった実装や, 数字がどうやって表現されているかをgdbを用いて調べてみます.
この記事はpartake.inの12月24日分のものです。
Haskellのコンパイル順序
I know kung fu: learning STG by exampleによるとHaskellはGHCの中で次のような流れでコンパイルを進めます.
- Parse tree
- Core (Syntax sugarがなくなります)
- STG (Spineless Tagless G-machine language)
- C--
- backend 下の中から一つ選ばれます
最後のbackendは3つのうちから選べます. Cがわかりやすそうなので、この記事ではC--のあとC言語を経由するHaskellのコンパイル順序を考えてみることにしました. ちなみに最新のghcではCを経由するコンパイルオプション(-fvia-C)は使えなくなっているそうです.
Tracing the compilation of Hello Factorial! : Inside 245-5Dの記事ではコンパイル段階をひとつひとつ追って説明してくれているので外観をつかむのに役立ちました.
Spinless Tagless G-machine
Syntax sugarが取り除かれたCoreのあとはHaskellのコードはSTG languageに変換されます. STGとは, 論文Implementing lazy funcitonal languages on stock hardware: the Spineless Tagless G-machineのAbstractによると,
The Spineless Tagless G-machine is an abstract machine designed to support non-strict higher-order functional languages.
Spineless Tagless G-machineは正格評価でなく(Non-strict semantics. 引数に定義されていない値があっても関数が未定義でない値を返すことができる.), 高階関数をサポートする関数型言語をサポートする抽象機械である」とありますが, つまりはHaskellのための抽象機械です.
This presentation of the machine falls into three parts. Firstly, we give a general discussion of the design issues involved in implementing non-strict functional languages. Next, we present the STG language, an austere but recognisably-functional language, which as well as a denotational meaning has a well-defined operational semantics. The STG language is the "abstract machine code" for the Spineless Tagless G-machine.
抽象機械っていうのは実際に存在する機械じゃなくて, 紙や頭のなかで存在するものでプログラムが与えられたらそれを決まった手順(Operational Semantics)によって評価する空想上の何かです. STGが処理する言語をここではSTG Languageと呼んでいます.
Lastly, we discuss the mapping of the STG language onto stock hardware. The success of an abstract machine model depends largely on how efficient this mapping can be made, though this topic is often relegated to a short section. Instead, we give a detailed discussion of the design issues and the choices we have made. Our principal target is the C language, treating the C compiler as a portable assembler.
タイトルにもあるStock Hardwareとはよくわかりませんがつまり僕らが普段使っているコンピュータのCPUとメモリを持った機械のことだと思います. Stack machineじゃないんでしょうか. STG Languageは関数やパターンマッチを含んだ言語である一方で, 僕らが普段使っているCPUやメモリはレジスタやアドレスやラベルといったものしか使うことができないのでその間の橋渡しが必要で, それをうまくやると速い言語処理系になります. このAbstractではSTG languageを直接Assemblyに変換するのではなくC言語にmappingすることでその橋渡しを行っています. 上に書いたコンパイル順序のC backendがこれに対応するのでしょう.
STG language
STG言語がどんなものかを論文の中の例を見てみましょう.
map f [] = [] map f (y: ys) = (f y) : (map f ys)
というHaskellのコードが
map {} \n {f, xs} ->
case xs of
Nil {} -> Nil {}
Cons {y, ys} -> let fy = ({f, y} \u {} -> f {y})
mfy = ({y, ys} \u {} -> map {f, ys})
in Cons {fy, mfy}というSTG languageに対応します. ここで見られる言語の特徴は
- Pattern matchingはCase文にまとめられている. 上の例では関数定義によるPattern matchingが関数内のCase文にまとめられています.
- クロージャには引数, 自由変数, 更新可能フラグ(\n, \u)が明示的に付けられている
Closure in STG language
STG languageにおいてクロージャはというのは関数が定義されたときの引数の束縛の環境を覚えているデータ構造とその関数のことです.
クロージャは
{x, y} \u {a, b, c} -> (...)
のような形をしていて, この例ではx, yがこのクロージャが呼び出されるときの引数で, a, b, cはこのクロージャが定義されたときの引数の束縛, つまり自由変数です. \uというのはこのクロージャが更新可能かというフラグで, ここがuならば更新可能で, つまりこのクロージャが最初に評価された際にそのクロージャの値を更新して(キャッシュして)同じ評価が二回起こらないようにすることができます. いわゆるthunkです.
のちのちこれをより低レイヤーなC言語に置き換えることを考えるとクロージャは「実行可能なコードへのアドレスと, いくつかの自由変数へポインタが保存されているメモリの領域」になります.
ghcとSTG
上の例では論文に記載されているmapの例を取り上げましたが, 次はこのようなHaskellコードをコンパイルしてみましょう.
-- Core.hs {-# NOINLINE getIntMaybe #-} a = Just 3 getIntMaybe :: Maybe Int -> Int getIntMaybe mv = case mv of Just x -> x + 3 Nothing -> 16 main = print (getIntMaybe a)
STG languageの表現を見るには"--dump-stg"オプションを付けてコンパイルすると, 標準出力にSTG languageの表現をみられます.
$ ghc -c Case.hs -ddump-stg
==================== STG syntax: ====================
getIntMaybe_rbu =
sat-only \r srt:(0,*bitmap*) [mv_sng]
case mv_sng of wild_sno {
Data.Maybe.Nothing -> GHC.Types.I# [16];
Data.Maybe.Just x_snj ->
let { sat_snp = NO_CCS GHC.Types.I#! [3];
} in GHC.Num.+ GHC.Num.$fNumInt x_snj sat_snp;
};
SRT(getIntMaybe_rbu): [GHC.Num.$fNumInt]
sat_sns =
\u srt:(0,*bitmap*) []
let { sat_snq = NO_CCS GHC.Types.I#! [3]; } in
let { sat_snr = NO_CCS Data.Maybe.Just! [sat_snq];
} in getIntMaybe_rbu sat_snr;
SRT(sat_sns): [GHC.Num.$fNumInt]
Main.main =
\u srt:(0,*bitmap*) [] System.IO.print GHC.Show.$fShowInt sat_sns;
SRT(Main.main): [System.IO.print, GHC.Show.$fShowInt, sat_sns]
:Main.main =
\u srt:(0,*bitmap*) [] GHC.TopHandler.runMainIO Main.main;
SRT(:Main.main): [GHC.TopHandler.runMainIO, Main.main]もとのHaskellのコードとSTG languageを比べると, Haskellでは"x + 3"という表現されていたものがSTG languageの段階では"GHC.Num.+ GHC.Num.$fNumInt x_snj sat_snp"になっています. Haskellでは2引数だったこのIntの足し算が3引数になり, 新たに第1引数にGHC.Num.$fNumIntというものが与えられています. (+)演算子はNum型クラスによって宣言されています.
Prelude> :i (+) class (Eq a, Show a) => Num a where (+) :: a -> a -> a ... -- Defined in GHC.Num
同じ型クラスでもクラスのインスタンスがその演算子をどう実装するかによって挙動が異なります. 新たに加えられた第一引数"GHC.Num.$fNumInt"はこの実装を保持する辞書(dictionary)の役割を持っていて, "GHC.Num.+"は, これを使ってInt型の(+)演算子の実装を参照します.
C--
STG languageのあとはC--です. STGは高階関数を持っていたり抽象データ型を用いたcase文を持っていたりしているのでレジスタやメモリしかないCPUでは扱えません. なのでC--という言語に変換してからAssemblyにします. ここではCに変換されたコードを見ていきます.
Function call
実際にコードを見る前にC-backendなC--でクロージャ(関数)がどのようにして表現されているかを紹介します. クロージャはinfo table, entry code, closureという三つのメモリ領域からなります.
info tableは関数(クロージャ)のentry codeへのポインタや引数の数の情報を保持しているメモリ領域です.
entry codeはその関数の命令列の先頭についているラベルで、C言語の関数です. entry codeには関数の場合(+thunkの場合)と継続の場合があります. それぞれ到達したときのR1の中身やスタックの状態などにルールがあり、例えば継続の場合は直前に評価されたものへのポインタがR1に入っています.
closureはinfo tableへのポインタと自由変数へのポインタを保持しています.
func_info = {
&func_code, // pointer to entry code, followed by arity information etc.
....
}
func_closure = { // pointer to info table and free variables
&func_info,
free_variable1,
free_variable2
...
}
void func_code (void) { // actual machine code
....
}
Z-encoding
Haskellではいろんなシンボルが現れるので, それをC言語の関数名に使えるような名前に変換しないといけません. それがz-encodingというものです. 例えばSTG Languageに現れるbase_GHCziNum_zdfNumInt_closureはGHC.Numや, $fNumIntがHaskellの世界でのシンボルであったものになります. リストの連結に使われる"++"演算子を調べたければC--のコードの中では"zpzp"という文字列を探すことになります.
symbol names · Wiki · Glasgow Haskell Compiler / GHC · GitLab
デバッグフラグのついたC--のコードを手に入れる
この記事ではC言語に落とし込まれたC--のコードを見ていきます. ghcの裏でどんなコマンドが実行されているかは-vフラグを立てると見れます.
ghc -v Case.hs
プログラムの挙動を見るには実際に動いているものをGDBで止めるのがいいですね. C言語で表現されたC--のコード(hcファイル)をGDBでデバッグしながら見るには次のようなコマンドを実行するとhcファイルと, hcファイルの行番号のデバッグ情報が入った実行ファイルが手に入ります.
ghc -optc-ggdb -keep-tmp-files -tmpdir ./tmp -v -fvia-C -keep-hc-files Case.hs
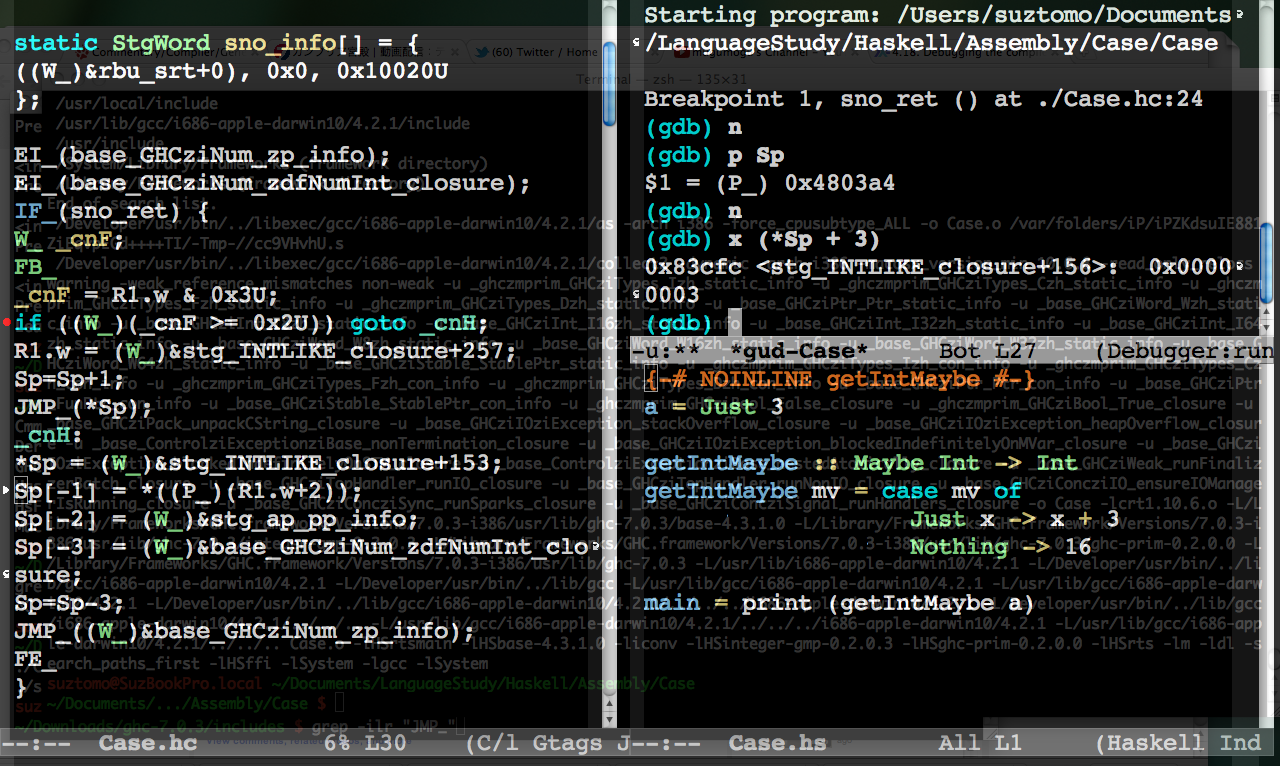
この実行ファイルをEmacsでソースコードをみながら特定の場所にブレークポイントを挿入したり, 変数の値を対話的に表示させることができます. 次のスクリーンショットでは左側にhcファイルを表示させ, 右上にgdbのウィンドウ, 右下にはHaskellのコードを表示しています. hcファイルの行頭に赤丸が表示されているのがブレークポイントで, 三角で表示されているのが実行されようとしている行です.
case文
-- Core.hs {-# NOINLINE getIntMaybe #-} a = Just 3 getIntMaybe :: Maybe Int -> Int getIntMaybe mv = case mv of Just x -> x + 3 Nothing -> 16 main = print (getIntMaybe a)
このコードをコンパイルすると, "case文によりmvを評価する"部分は
IF_(rbu_entry) {
FB_
if ((W_)(((W_)Sp - 0xcU) < (W_)SpLim)) goto _cnR;
R1.w = *Sp;
*Sp = (W_)&sno_info;
if ((W_)((R1.w & 0x3U) != 0x0)) goto _cnU;
JMP_(*R1.p);
_cnR:
R1.w = (W_)&rbu_closure;
JMP_(stg_gc_fun);
_cnU:
JMP_((W_)&sno_info);
となります.
特徴的な箇所をいくつか見ていきます.
スタックとヒープのサイズチェック
if ((W_)(((W_)Sp - 0xcU) < (W_)SpLim)) goto _cnR; ... _cnR: R1.w = (W_)&rbu_closure; JMP_(stg_gc_fun);
これはスタックのサイズを比べています. Spはスタックの先端を指すポインタが入っていて, SpLimには確保されたスタックの限界が入っています. これからスタックを12バイトのばそうとしているので, それが限度をこえてしまうならばスタックをのばすためのコードに飛びます. 飛ぶ前に_cnRというラベルの部分でまたここにもどってこられるようにこのentry codeへのポインタを保持しているclosureへのポインタをR1に保存しておきます.
ヒープも同じように変数HpとHpLimがあり、ヒープに何かが割り当てられる前に長さのチェックが行われます.
if ((W_)((W_)Hp > (W_)HpLim)) goto _coD;
クロージャの2重評価をポインタのタグにより避ける
if ((W_)(((W_)Sp - 0xcU) < (W_)SpLim)) goto _cnR; R1.w = *Sp; *Sp = (W_)&sno_info; if ((W_)((R1.w & 0x3U) != 0x0)) goto _cnU; JMP_(*R1.p);
スタックが十分確保されていればそのまま処理をすすめます. ここではcaseによって評価されようとしているクロージャが既に評価済みかどうかをそのクロージャのポインタのタグによって区別しています. クロージャのタグは下位2ビットのことで既に評価がされていれば下位にビットが0以外のタグが入って, このときそのアドレス値はそのまま(下位2ビットを気にすることなく)info tableへのpointerになっているのでそこにジャンプします.
クロージャのアドレスはword(4バイト)単位でしか指定されないというルールにすることで下位2ビットをタグとして利用することができるのです.
R1には評価しようとしているクロージャの(info tableへの)アドレスがはいっています.
コンパイラのソースコードのincludes/stg/TailCalls.hにJMP_の定義が書かれていて,
#define JMP_(cont) \ { \ void *__target; \ __DISCARD__(); \ __target = (void *)(cont); \ goto *__target; \ }
とあります. つまり, JMP_の引数をdereferenceしてその先に飛びます. JMP_をinfo pointer, つまりinfo tableへのポインタに対して呼ぶということは, info tableの第一要素にはentry codeへのポインタが入っているので, そのentry codeへ実行を移すということになります.
caseの条件分岐
mvが評価された後でcase文の条件分岐の部分は
IF_(sno_ret) {
W_ _cnF;
FB_
_cnF = R1.w & 0x3U;
if ((W_)(_cnF >= 0x2U)) goto _cnH;
R1.w = (W_)&stg_INTLIKE_closure+257;
Sp=Sp+1;
JMP_(*Sp);
というようにC--にコンパイルされます. ここに現れるマクロや型はghcのソースコードのincludes/Stg.hに定義されています. 例えばIF_は以下のように定義されていて, 引数をとらない関数の定義に変換されるということがわかります.
#define IF_(f) static StgFunPtr GNUC3_ATTRIBUTE(used) f(void)
sno_retというのはcaseの対象となるクロージャが評価されたのちに呼ばれる継続です. 継続の場合はその前に評価されたクロージャのアドレスがR1という変数に保存されているという約束になっています.
R1というのはいろいろな用途に使われるUnion型を持っています. gdbでどんなものか見てみましょう.
(gdb) p R1
$3 = {
w = 4716274,
a = 0x47f6f2,
c = 4716274,
f = 6.60890751e-39,
i = 4716274,
p = 0x47f6f2
}
(gdb) whatis R1
type = StgUnion
(gdb) p R1.w
$4 = 4716274
(gdb) whatis R1.w
type = StgWord
(gdb) ptype StgUnion
type = union {
StgWord w;
StgAddr a;
StgChar c;
StgFloat f;
StgInt i;
StgPtr p;
}
(gdb) ptype StgWord
type = long unsigned intDebugging GHC-compiled code with gdbに便利そうなgdbのマクロがあります.
ポインタのタグによるコンストラクタの判別
_cnF = R1.w & 0x3U
これはR1の下位2ビットを取り出しています. R1にはHaskellコードの中のmvのクロージャへのポインタが入っているのですが, 実はこの中身を取り出さなくてもこのポインタが指す先がJustでできているものなのかNothingでできているものなのかがわかります. これがポインタのタグ付けです.
コンストラクタが4個以下の抽象データ型に対して, ポインタのタグ, つまりアドレスの下位2ビットを使ってそのコンストラクタを区別しています. ルールはポインタの下位2ビットが
という風になっているようです. *1
if ((W_)(_cnF >= 0x2U)) goto _cnH; R1.w = (W_)&stg_INTLIKE_closure+257;
つまり, この分岐ではmvの値が2番目以降のコンストラクタ(つまりJust)を使って構築されている場合に_cnHというラベルに飛びます. もしmvの値がそれ以外のコンストラクタ(つまりNothing)を使って構築されている場合にはジャンプせずに次のコードが実行されます.
R1.w = (W_)&stg_INTLIKE_closure+257; Sp=Sp+1; JMP_(*Sp);
R1に数字の16を表すデータを指すポインタを入れた後スタックの一番上に積まれているポインタへ戻り, その値をスタックから除きます.
レジスタとヒープポインタ, スタックポインタ
レジスタに保存されています.
(gdb) info registers
eax 0x2 2
ecx 0x480000 4718592
edx 0x47f6fc 4716284
ebx 0x83fcc 540620
esp 0xbfffcf60 0xbfffcf60
ebp 0x4803a4 0x4803a4
esi 0x47f6f2 4716274
edi 0x47f6fc 4716284
eip 0x21b8 0x21b8 <sno_ret+40>
eflags 0x293 659
cs 0x1b 27
ss 0x23 35
ds 0x23 35
es 0x23 35
fs 0x0 0
gs 0xf 15
(gdb) p R1.p
$22 = (StgPtr) 0x47f6f2
(gdb) p Sp
$23 = (P_) 0x4803a4
(gdb) p Hp
$24 = (P_) 0x47f6fcそれぞれのレジスタに入っている値とSp, Hp, R1の値を比べてみると
- R1 : esi
- Sp : ebp
- Hp : edx (or edi?)
というふうにレジスタに割り当てられているようです.
数字の表現
HaskellのIntの表現は非ボックス化型を用いて表現されています. http://www.kotha.net/ghcguide_ja/latest/primitives.html
特に数字が-16から+16の間の場合コンパイラが用意してくれたテーブルを使うことができます. 例えば,
*Sp = (W_)&stg_INTLIKE_closure+153;
という箇所があったので, ここが呼ばれたあとの状態をGDBで実行を止めてみました.
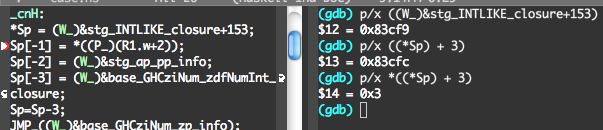
この(&stg_INTLIKE_closure+153)というアドレスの周りをみてみましょう. この値は既にSpに格納されていることを利用して,
(gdb) p/x *Sp $15 = 0x83cf9 (gdb) p/x *((*Sp) + 3) $16 = 0x3 (gdb) p/x *((*Sp) + 3+8) $17 = 0x4 (gdb) p/x *((*Sp) + 3+8*2) $18 = 0x5 (gdb) p/x *((*Sp) + 3+8*3) $19 = 0x6 (gdb) p/x *(*Sp -1) $20 = 0x4b948 (gdb) x *(*Sp - 1) 0x4b948 <ghczmprim_GHCziTypes_Izh_static_info>: 0x0065ff46 (gdb) x *(*Sp - 1 + 8) 0x4b948 <ghczmprim_GHCziTypes_Izh_static_info>: 0x0065ff46 (gdb) x *(*Sp - 1 + 8*2) 0x4b948 <ghczmprim_GHCziTypes_Izh_static_info>: 0x0065ff46
メモリの様子を図にすると次のようにGHC.Types_I#_staticへのinfo tableのアドレスと, 数字が交互に並んでいることがわかります.
|Address | Content
*Sp-1 ------------> |0x83cf8 | 0x4b948 <ghczmprim_GHCziTypes_Izh_static_info>
|0x83cfc | 0x3
|0x83d00 | 0x4b948 <ghczmprim_GHCziTypes_Izh_static_info>
|0x83d04 | 0x4
|0x83d08 | 0x4b948 <ghczmprim_GHCziTypes_Izh_static_info>
|0x83d0c | 0x5
|0x83d10 | 0x4b948 <ghczmprim_GHCziTypes_Izh_static_info>
...このメモリに対して0x83cf9が(0x83cf8+1)Spに入っています. これはこのポインタの指すclosureをタグ付けしているのでしょう.
つまり,
「このポインタが指す値は既に評価されており, このデータ型(GHC.Types_I#)の1番目のデータコンストラクタを使ったもので, I#のコンストラクタの引数は(その4バイトとなりにある)3の値がつかわれたもの」
と読むことができます.
ちなみにこの数字のテーブルはrts/StgMiscClosures.cmmの中で作られているようで, -16から16までの数字をサポートしているようです.
#define Int_hash_static_info ghczmprim_GHCziTypes_Izh_static_info ... #define INTLIKE_HDR(n) CLOSURE(Int_hash_static_info, n) ... section "data" { stg_INTLIKE_closure: INTLIKE_HDR(-16) /* MIN_INTLIKE == -16 */ INTLIKE_HDR(-15) INTLIKE_HDR(-14) ... INTLIKE_HDR(13) INTLIKE_HDR(14) INTLIKE_HDR(15) INTLIKE_HDR(16) /* MAX_INTLIKE == 16 */ }
というテーブルにより構成されています.
数字はGHC.Integer_smallInteger_closureを用いて作られる場合
まとめ
Glasgow Haskell Compilerの中で使われているSTG languageとC-backendのC--を紹介しました. 中間コード(hcファイル)をGDBを用いてデバッグすることにより実際のメモリレイアウトをインタラクティブに理解することができるということが伝わったら嬉しいです.
次はtanakhさんです.
今回扱えなかったもの
- hcファイルでの関数適用
- INTLIKE以外の数字の構築方法
- リストの表現
- Thunkを実装するstg_bh_upd_frame